
このブログってなんなの?
今、この「模索する俺たち」というブログをリニューアルしようとしています。
なぜリニューアルするのかというと、はじめにちょっと適当にブログを作り始めたのでデザイン(htmlというかcssというか)的にちょっと無理しているところがあったりするので、その辺をすっきりさせたいとかが理由です。
それによりちょっと見た目が変わるようなところがあるのですけど、ついでに各記事のカテゴリーの分け方も変えたいと思っています。
というのも、カテゴリーも適当に作ったので「雑記」が300件あって、「kindle」が5件とかアンバランスになったりしているのを是正したいです。
それではどういうカテゴリーにしたらいいのかなと思ったのですけど、考えてみたらこのブログって主に何書いてんのかわかんないなと思いました。
日々、好きなことを適当に書いているためです。
で、どうにか分析しようと思ったのですけど、いろいろ調べていたら「WordCloud」というのがあって、それでよく使う単語などをわかりやすく図示できるようです。
これができるとおもしろそうだなと思いました。
できあがり
で、結論をいうとこれです。
今までの各記事のタイトルでWordCloudを作ったらこうなりました。

おお、かっこいいし、おもしろい……。
出てくる単語の数で文字の大きさが変わるのですけど(色はランダム)、割とくっきりしましたね。
大きいのを見ると、
- メモ
→メモ(雑記)としていろいろ書いたから多いですね。 - スマホ
→特に初期のころはスマホとかガラケーの話を書きまくっていたので多いですね。 - 引っ越し
→確かに、このブログ始めてからなぜか3回も引っ越したので多くなりましたね。 - ゲーム
→好きだからそうなりますね。 - Switch
→好きだからそうなりますね。
っていうか、なんか丸見えで恥ずかしい気もしないでもありません。
というわけで、このWordCloudの図を新カテゴリーの参考に……しようかと思いましたが、すでに「引っ越し」とかもそれっぽいカテゴリーあるし……、やっぱり別途自分で考えることにします。
WordCloudさん、ありがとうございました。
WordCloudの使い方、作り方についてのメモ
というわけで、ここからは話題を変えて、今回作ったWordCloudの作り方をメモしておきたいと思います。
ちょっと大変でしたけどできたら見た目のかっこよさもあって達成感がありました。
以下、ほぼ個人的なメモとしてわかったふりして書いていますが、詳しいことはよくわかっていませんのでよろしくお願いします。
用意したもの
1.Windows10で動くUbuntu(WSL環境)
先日、インストールしたやつを使いました。↓
2.WordCloudにするデータ
ブログの記事のタイトルを入れたテキストファイル(改行区切り)を用意しました。(普通の文章だったら別に改行入れずに続けて書いてもよさそう)
Linux(Ubuntu)で使うので、「サクラエディタ」で文字コードUTF-8、改行コードLFにして保存しました。
3.日本語フォント
WordCloudに使う日本語フォントが必要です。
何やら拡張子が.otfのフォントファイルが必要みたいです。(たぶん)
今回は「やさしさアンチック」を使わせていただきました。

パソコンに最初から入っているフォントを使うと、ネットで公開するにあたってはライセンス的に怒られる場合があるので、権利関係が大丈夫なフォントを見つけて使った方がいいですね。
WordCloudを使えるようにする
基本的な流れはこちらを参考にさせていただきました。

ただし、私は今回WSL環境というのでやろうとしていてちょっと環境が違うので、以下の通りちょこちょこ改変しながらいきました。
まず、適当なフォルダに、上記のテキストデータとフォントファイルを入れて、Shift押しながらフォルダ内の空いているところを右クックしてLinuxシェルを開きます。
python3と打ってみて、Pythonのバージョン3が起動することを確認したらPythonを
exit()で終了。
続いて、以下でpip、wordcloud、janomeをインストールする。
sudo apt-get install python3-pip
python3 -m pip install wordcloud
python3 -m pip install janome※Python3では上記の形のコマンドが必要でした。こちらを参考にしました。

うまくインストールされていないと、後で
ModuleNotFoundError: No module named 'wordcloud'みたいなエラーが出ます。(出ました)
作る
ここまでで環境の準備は完了です。
後は実際に作ります。
辞書のファイルを作っておく
janomeというプログラム?が日本語の文章をうまいこと単語などに分割してくれるのですけど、たまにうまくいかないときがあります。
私は「スマホ」が「スマ」と「ホ」に分かれてしまったので、最初はでっかく「スマ」と書かれた画像が生成されまして何事かと思いました。
というわけで、微妙な単語については、こうですよと教えてあげる必要があります。
※詳しくはこちら。

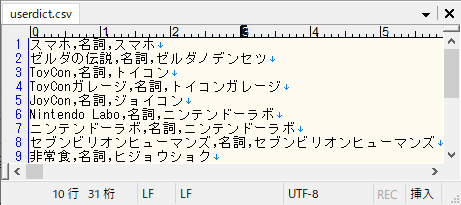
で、私は最終的にはこういう感じで辞書のファイルを作っていくつか登録しました。
(さっきと同じフォルダにuserdict.csvという名前でUTF-8、LFで作成)
実際には、まずWordCloudの画像を作ってみて、おかしいのがあればこのファイルに書き足してもう一度作ってみる……みたいな流れになります。
WordCloudを作るスクリプトファイルを作る
後はPythonのスクリプトを作っておきます。(ベースは最初のサイトよりいただきました。)
ファイル名は適当にwc.pyとしてUTF-8のLFで同じフォルダに保存しました。
なお、テキストファイル(title.txt)からデータを読み込むためこちらを参考にしました。

▼wc.py ここから▼
## 分かち書き
## pip install janome
from janome.tokenizer import Tokenizer
tokenizer = Tokenizer("userdict.csv", udic_type="simpledic", udic_enc="utf8")
text = ''
f = open('title.txt')
line = f.read()
f.close()
stop_words = [ u'ため', u'やつ', u'こと', u'か月', u'amp', u'とき', u'ところ', u'みたい', u'週間', u'kg',
u'もの', u'さん', u'よう', u'そう', u'がい', u'ほう']
tokens = tokenizer.tokenize(line)
for token in tokens:
parts = token.part_of_speech.split(',')
if (parts[0] == '名詞'):
text = text + ' ' + token.surface
print(text)
## 引き続きWordCloud
from wordcloud import WordCloud
wordcloud = WordCloud(background_color="white", font_path="./07YasashisaAntique.otf",
width=1200,height=800,stopwords=set(stop_words), colormap='Dark2').generate(text)
wordcloud.to_file("./test.png")▲ここまで▲
このスクリプトの最後の方の、font_pathにフォントのファイル名を指定します。
あと、中盤のstop_wordsというのが調整が必要なところで、表示する必要がない言葉をここに書き連ねておきます。
一度WordCloudを作ってみると、表示する必要のない文字が出てくると思うのでそれを見てここを修正して、再作成という流れになります。
ここまでのファイルの準備がうまくいっていれば、Linuxシェル上で
python3 wc.pyとやると処理が走って、フォルダに”test.png”というファイルが出来上がっているはず。
調整していく
一度出来上がるとかなり楽しくなってきます。
後は、うまくいっていない単語を辞書ファイルに登録したり、不要な単語をstop_wordsに追加したり。
場合によっては元のデータを開いてうまくいかないところを置換して修正したり。(「Toy-Con」を「ToyCon」に置換してしまったり、「Nintendo Labo」と「ニンテンドーラボ」といった表記ゆれを統一したり)
あと、色のパターンを変えたり…。
※色の変え方はこちらを参考にしました。

作成するたびに配置や配色が変わったりするのでなかなか面白いものがあります。

私はこの調整の工程で1時間ほど遊んでしまいました。(それでもまだ変な文字列が出ているところもありますが)
まとめ
というわけで、後半やはり個人的なメモになってしまいましたが、とにかくWordCloudってのが面白かったということだけお伝えしたかったです。
おわり。




コメント